In 2014, Szegedy et al. published an ICLR paper with a surprising discovery: modern deep neural networks trained for image classification exhibit the following vulnerability: by making only slight alterations to an input image, it’s possible to drastically fool a model that would otherwise classify the image correctly (say, as a dog), into outputting a completely wrong label (say, as a banana). Moreover, this attack is possible even with perturbations that are so tiny that a human couldn’t distinguish the altered image from the original.
These doctored images are called adversarial examples and the study of how to make neural networks robust to these attacks is an increasingly active area of machine learning research.
This adversarial noise can be made robust. Labsix, a group of MIT students, showed that one can create adversarial examples in the physical world by 3d-printing a physical object, now affectionately called the adversarial turtle, that is classified as a rifle by state-of-the-art deep nets. Here it is:

The magic of the attack is on the turtle shell pattern. It looks benign to humans but completely confuses models, even under different lighting conditions, camera noise and rotations.
In perhaps a more alarming example, Evtimov et al. created adversarial stickers for road signs:

Remarkably, standard road sign classification neural networks classify these as speed limit signs under various angles and lighting conditions.
How can we defend against such attacks? A deluge of recent papers have proposed methods for defenses and counter-attacks. The problem is surprisingly complex and many natural defenses can be easily defeated by creating new adversarial images, designed to break the defenses.
The tremendous attention by the research community is well justified. Beyond security concerns, adversarial examples illustrate that our modern complex models can be making correct predictions for completely wrong reasons.
These attacks can be created in various ways. The first papers proposed attacks that modified the values of the pixels, while ensuring that the modified image x’ remains close to the original reference image x in some simple distance (e.g. Euclidean or max absolute difference). However, recent results showed that alternative attacks can create adversarial examples by applying tiny rotations or other imperceivable spatial transformations. Two images x and x’ may be far in Euclidean distance but perceptually near-identical.
The initial idea: incorporating generative models.
In our recent paper, we use generative models to defend against adversarial attacks. A generative model is a method to produce artificial data that looks statistically like the real data in the domain of interest. The goal is to learn the distribution of the original data using deep learning. Modern generative models (Generative adversarial networks and Variational AutoEncoders) have been making tremendous breakthroughs for this problem recently.
Trained on images of humans or animals, a generative model should be able to produce new images that look natural. An ideal generative model can produce any natural image and assign zero probability to non-natural images, in other words it is an excellent prior distribution.
Modern GANs (like Progressive Growing GANs) can produce high-quality synthetic photographs of human faces as can be seen in this video. A snapshot of generated faces from that video are shown here:

A key property of these generative models is that they can generate images from low-dimensional latent space: to generate faces, for example, a GAN takes as input a vector z that is only 100-dimensional and outputs a vector of dimension 64*64*3 (64×64 pixels and three color channels).
Using GANs for Defense
Assume that we have access to a generative model G(z) that has already been trained for the data we are working with. Our initial idea is very simple: before feeding an input x into a classifier C, we project it on the range of the generator. In other words, find the closest point to x that G(z) is capable of producing and feed that as an input to the classifier.
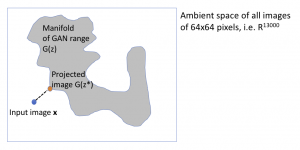
The intuition is that adversarial examples exist because an original natural image x was perturbed into a point that lies far from the manifold of natural images. Our classifier has never been trained on objects far from natural images so it can behave in unexpected ways. The natural image manifold is low-dimensional but the noisy objects that can be reached with even tiny perturbations, is very high dimensional and hence very hard to train on.
This is what we thought. Surprisingly, we were able to attack our own method. It turns out that there are adversarial examples even on the manifold of the generative model, at least for the GANs we trained.
Adversarial examples on the manifold
To test our method, we tried to find a way to attack it. Our idea is to search for pairs of latent codes z,z’ that produce images that are nearby but classified very differently. By solving a min-max problem we obtained several such natural adversarial examples.
An example is shown here, for a face gender classifier.

Our classifier labels the left image as ‘man’ with confidence 0.99 and the right one as ‘woman’ with confidence 0.99. This is problem, since a human can barely see any difference between these two images. A robust classifier should have a smooth transition of uncertainty and classify these images as man or woman with lower confidence, since they are near the decision boundary.
Interestingly there are tiny differences (e.g. on lips and eyes) but the confidence of the classifier is unjustifiable. Both of these images lie on the manifold of natural images spanned by a GAN we trained for human faces.
We therefore found that projecting onto the range of GAN does not successfully defend against all adversarial examples. This was also discovered independently in the recent ICLR attack paper and also supported theoretically in the recent paper on adversarial spheres.
The problem may be because our GAN or classifier are problematic, or perhaps because natural adversarial examples cannot be avoided.
We should point out that independently of our work, the Defense-GAN paper proposed a near-identical method of defending by projecting on the range of a GAN. Defense-GAN was compromised in the Obfuscated gradients paper by Athalye et al., that defeated many of the ICLR proposed defenses. The method Athalye et al. used to attack Defense-GAN is very similar to the attack we just described. The difference is that they keep one image x fixed and search only over the other x’, as opposed to searching over pairs.
The Robust Manifold Defense
So far, it seems like leveraging generative models’ ability to only produce natural images is not sufficient to defend against adversarial examples. What we notice, though, is that we can combine this property with the low-dimensional latent space property to come up with what we call the robust manifold defense. Rather than using a GAN to denoise inputs, we instead use the generative model as a way to reduce the dimension and defend with adversarial training.
The method of adversarial training, proposed by Goodfellow et al., provides a way to convert any attack into a defense. Generate adversarial examples using the attack method, associate them with the correct labels and add to the dataset as new training examples. It was recently shown that adversarial training can be seen as a form of robust optimization (as shown by Madry et al. and Shaham et al. ). Adversarial training seems to be one of the very few methods that withstands attacks, like the recent attack to ICLR defenses.
The robust manifold defense makes a classifier robust by performing adversarial training on the GAN manifold. The benefit is that we need to perform robust optimization in significantly lower dimensions.
We apply this procedure using the adversarial images we find on the manifold, to obtain a new robust classifier. Our final classifier is much less confident near the decision boundary, as desired. The label confidence of the robust classifier is shown in the green bars.

Under the robust optimization view, the robust manifold defense offers the following benefits:
- It reduces the dimensionality of the robust optimization problem: because we can now robustify our classifier in a 100-dimensional space instead of a much higher dimension, the robust optimization problem should be easier to solve.
- It limits the problem to inputs we care about: we can think of the Robust Manifold Defense as robustifying a classifier over the space of natural images. That is, if x is an image of random noise, we do not really care if x is classified differently than x + ε, since x itself is not a valid input.
- It builds a stronger defense: one of the key observations under the robust optimization view is that adversarially training under stronger attacks makes the defense also stronger. In the attack we made, the adversary has much more power than usual (since they can pick both z and z’), so adversarial training yields a stronger defense.
Conclusions
Adversarial examples are important. They show how little we understand about our shiny new classifiers and how fragile they can be.
The robust manifold defense is an efficient way of performing adversarial training, which is currently, to the best of our knowledge, the state of the art defense.
The main limitation is, of course, that we need access to a generative model for the data we are classifying. This is often hard to create and in our preliminary work we tried to use the deep image prior as a replacement when a good generative model is not available. We do not think this is as secure as the robust manifold defense, but is still a sensible idea when no generative model is available.
There are many more avenues to investigate regarding defense against adversarial examples. As we are discovering, adversarial examples can be created for other domains like audio or text. The next time somebody plays some music in your home, your Alexa may hear an order request that you did not even perceive!
Alex Dimakis would like to thank Andrew Ilyas and Zack Lipton for numerous comments and feedback that improved this post.
“Remarkably, standard road sign classification neural networks classify these as speed limit signs under various angles and lighting conditions.”
I don’t believe this is true. IIRC, in that paper they only test a model that they trained themselves which used tiny images (32×32) and had decent but not great accuracy.